Main aim of the study
This work presents opportunities, achievements, and future challenges in using computational analytics to better understand the connection between CS and the SDGs. The work in its status does not fully cover SDGs in CS, but it evaluates and shows the potential of the text-classification techniques for identifying SDGs in CS project descriptions and for assessing trends in connection of CS and SDGs based on available data.
This study analyses different automatic classifiers by comparing the results obtained from their application in a sample of 208 CS project descriptions. The main aim is to present the benefits and limitations of these techniques (nCoder, ESA, OSDG and BERT), but also provides a discussion of the potential benefits of using data from CS projects to map the 17 SDGs. Second, this work has been extended by analysing all the project descriptions in English collected in the CS track database.
Period addressed by the study
A total of 56 websites have been used to extract project descriptions. The list of websites (CS platforms and non CS platforms) and projects is consistently updated for the duration of the project (2019-2022). The data has been extracted from the CS Track database.
Research question
Our main research question is: How can a data analytics approach based on web-based data mining and automatic classifiers contribute to the reporting of SDGs related to CS activities and projects?
Research Context
Previous students have discussed how traditional data sources provide insufficient knowledge for measuring the United Nations Sustainable Development Goals (SDGs). Data related to SDGs are sourced primarily from global databases maintained by international organisations, national statistical offices and other government agencies. Recent studies show the value of using data from Citizen Science (CS) for assessing the SDGs. The online presence of CS, especially via online CS platforms provides a rich context of data. In this scenario, the role of computational data science is key. This work explores and exemplifies opportunities for combining web-data mining techniques and automatic classifiers to enhance the understanding of the interrelation between CS and the SDGs.
Research Methods applied
A descriptive research approach. Combining qualitative research coding (manual content analysis) with automatic classification based on the application of three different methods: nCoder, ESA and OSDG.
Procedures applied
A subset of 208 projects from 16 CS different platforms were randomly selected from the CS Track DB with the following criteria: project descriptions should be in English; platforms should contain a list of projects situated in Europe or should be projects conducted online.
The method proposed by Fraisl et al. was followed to extract and review SDGs targets and indicators metadata. The review process was done by 3 researchers to identify a list of keywords to be applied for SDG classification purposes. In this process, the list published by Monash University and Australia S.D.S.N. was used. Then, manual coding was conducted by 2 researchers and 2 research assistants (n=4) of the 208 project descriptions. New keywords emerged from the manual coding process. The initial manual coding provided a ground truth against the performance of the three methods (i.e nCoder, ESA and OSDF) to evaluate the application of the selected automatic classifiers. In the corresponding full report of this study, we explain the reasons for selecting these automatic classifiers. The figure below illustrates the process followed to classify the dataset.
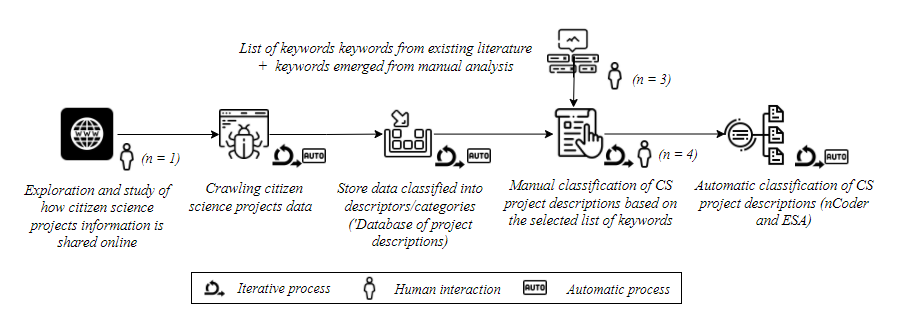
Dataset preparation and manual coding process.
Summary of results/findings
As the main contribution, this study shows how automatic classifiers can be used to map CS data with SDGs. Additionally, we provide a discussion of the techniques covered in this study by considering their advantages and limitations when applying each technique to classify CS project descriptions with SDGs.
We observe coincidences with results from previous authors regarding which SDGs are more representative in CS. The most represented ones are SDG#4 (Quality Education), SDG#11 (Sustainable Cities and Communities), SDG#13 (Climate Action) and SDG#15 (Life on Land). The case of SDG#10 (Reduced inequalities) is a curious case to be further investigated in the future. Similarly, in the case of SDG#4, SDG#10 seems to be a transversal SDG that can be associated with multiple disciplines.
An interesting finding shows how SDGs have dependencies among them, this is shown through a comparative analysis of SDG associations to the selected sample of projects. The most common associations are SDG#5 with SDG#8; SDG#6 and SDG#14; SDG#4 and SDG#10; SDG#3 and SDG#10.
Conclusion
In summary, when comparing the three main techniques used in this study: (1) the results obtained using nCoder are more aligned with the results of the manual classification, but the process can be overall time-consuming and later using a trained classifier is not possible. (2) In the case of ESA, the effort required from human coders is minimal, but the use of Wikipedia (as a main and unique source of knowledge in this case) constrains the quality of the results obtained. (3) When comparing the F1-Scores obtained with each technique, the ones from OSDG are lower than the ones obtained from the other techniques.
Additionally, and only in terms of discussion, we had into account the use of deep learning models such as BERT mainly because this is becoming the state-of-the-art model solution for multiple natural language processing tasks. Although obtaining satisfactory amounts of training data to train machine learning models is a challenge, techniques such as BERT can provide more accurate results (also considering multiple languages) in the future.
Annexes
- The paper/full report concerning this study is currently under review. Contact the corresponding author (patricia.santos@upf.edu) if you have interest to receive further information.
References
Kestin, T., van den Belt, M., Denby, L., Ross, K., Thwaites, J., & Hawkes, M. (2017). Getting started with the SDGs in universities: a guide for universities, higher education institutions, and the academic sector.
Fraisl, D., Campbell, J., See, L., Wehn, U., Wardlaw, J., Gold, M., … & Fritz, S. (2020). Mapping citizen science contributions to the UN sustainable development goals. Sustainability Science, 15(6), 1735-1751.
Photo by charlesdeluvio on Unsplash.